이번 글은 cs231n 2강에서 다뤘던 수식이나 알고리즘을 직접 파이썬으로 구현해서 작성했다.
✍️ L1 Distance

import torch
import numpy as np
def l1_distance(arr1, arr2):
tensor1 = torch.tensor(arr1, dtype=torch.float32)
tensor2 = torch.tensor(arr2, dtype=torch.float32)
distance = torch.sum(torch.abs(tensor1 - tensor2))
return distance
arr1 = [[56,32,10,18],[90,23,128,133],[24,26,178,200],[2,0,255,220]]
arr2 = [[10,20,24,17],[8,10,89,100],[12,16,178,170],[4,32,233,112]]
print(l1_distance(arr1,arr2))
- 단순하게 L1 거리 공식을 구현하였다. torch에서 제공하는 abs, sum 같은 내장함수를 써서 계산을 했다.
- 숫자는 cs231n 2강의 예시를 그대로 사용하였고, 같은 값이 출력됨을 확인할 수 있다.
- 공식에서도 볼 수 있듯 행렬의 각각 원소를 빼준 것에 절댓값을 씌운 값을 다 더해준다.
✍️ L2 Distance
import torch
def l2_distance(arr1, arr2):
ten1 = torch.tensor(arr1, dtype=torch.float32)
ten2 = torch.tensor(arr2, dtype=torch.float32)
distance = torch.sqrt(torch.sum(torch.square(ten1 - ten2)))
return distance
arr1 = [[56,32,10,18],[90,23,128,133],[24,26,178,200],[2,0,255,220]]
arr2 = [[10,20,24,17],[8,10,89,100],[12,16,178,170],[4,32,233,112]]
print(l2_distance(arr1,arr2))- 유클리드 공식으로 더 잘 알려진 거리 공식
- L1과 비슷한 방법으로 구현했으며, 위 사진의 공식과 같이 차의 제곱의 합을 제곱근으로 만들어 준다.
✍️ Nearest Neighbor
import torch
# L1 거리 구하기
def l1_distance(arr1,arr2):
distance = torch.sum(torch.abs(arr1 - arr2))
return distance
# 랜덤값으로 3*3 배열을 30개 만든다. (학습 데이터셋에 해당된다.)
matrix_list = torch.randint(0,10,(30,3,3))
# 0~4까지 수 중 랜덤하게 1*30 배열로 만든다. (클래스에 해당)
labels = torch.randint(low=0, high=5, size=(1,30))
# 새로 들어온 데이터이다.
new_data = [[4,5,6],[7,8,9],[10,11,12]]
# tensor로 변환시켜줌
t_new_data = torch.tensor(new_data, dtype=torch.float32)
t_i = torch.tensor(matrix_list,dtype= torch.float32)
# 거리를 저장할 배열을 만든다.
distances = torch.zeros(len(t_i))
# 모든 학습된 데이터셋에 대해 거리를 구해준다.
for i in range(len(t_i)):
distances[i] = l1_distance(t_new_data, t_i[i])
# 그 거리 중 최소값이 있는 인덱스를 찾는다.
nearest_index = torch.argmin(distances).item()
# labels배열에서 최소값을 가진 레이블을 찾는다.
predicted_label = labels[0][nearest_index]
# 예측된 레이블이 출력된다.
print(predicted_label)- L1 거리 공식을 사용하는 NN 알고리즘이다. 이렇게 구현하는게 맞는지는 모르겠으나 내가 이해한대로 파이썬으로 구현했다.
- 알고리즘은
- matrix_list 라는 3*3 배열이 30개 존재하는 list에서 new_data랑 하나하나 거리 계산을 한다.
- 최소 거리에 해당하는 인덱스를 찾는다.
- labels에서 인덱스를 넣어 레이블 값을 찾는다.
- 예측된 레이블을 출력한다.
- 말로 하면 간단한 알고리즘이라 짧을 줄 알았는데 생각보다 길게 나와서 놀랐다.
- 그리고, 데이터 값이 랜덤이라 뭔가를 분류하는 그런 모델은 아니다. (그저 알고리즘을 구현한 것)
✍️ K - Nearest Neighbor
import torch
from collections import Counter
# L1 거리 구하기
def l2_distance(arr1,arr2):
distance = torch.sqrt(torch.sum(torch.square(arr1 - arr2)))
return distance
# 랜덤값으로 3*3 배열을 30개 만든다. (학습 데이터셋에 해당된다.)
matrix_list = torch.randint(0,10,(30,3,3))
# 0~1까지 수 중 랜덤하게 1*30 배열로 만든다. (클래스에 해당)
labels = torch.randint(low=0, high=2, size=(1,30))
# 새로 들어온 데이터이다.
new_data = [[4,5,6],[7,8,9],[10,11,12]]
# tensor로 변환시켜줌
t_new_data = torch.tensor(new_data, dtype=torch.float32)
t_i = torch.tensor(matrix_list,dtype= torch.float32)
# 거리를 저장할 배열을 만든다.
distances = torch.zeros(len(t_i))
test_size = 3
ypred = [0 for _ in range(test_size)]
max_index = [0 for _ in range(2)]
# 모든 학습된 데이터셋에 대해 거리를 구해준다.
for i in range(len(t_i)):
distances[i] = l2_distance(t_new_data, t_i[i])
# 최근접 인덱스를 K개(여기서는 3개) 뽑아낸다. 이때 나는 가장 작은 인덱스의 수를 999로 바꿨는데, 별로 좋은 방법은 아닌듯함
nearest_index = []
for j in range(test_size):
nearest_index.append(torch.argmin(distances).item())
distances[torch.argmin(distances).item()] = 999
# 또다시 K개의 예측값을 저장한다.이때 최빈값이 최종 레이블로 결정되기 때문에 카운팅도 해준다.
for k in range(test_size):
ypred[k] = labels[0][nearest_index[k]]
max_index[ypred[k]] += 1
# max_index 배열에서 가장 큰 값의 인덱스가 최종 예측된 레이블이다
most_label = max_index.index(max(max_index))
print("index:",nearest_index ," predict :",most_label)- NN 알고리즘에 K개의 최근접 인덱스를 뽑아내고, 최빈값을 최종 예측 레이블로 출력하는 과정을 추가했다.
- 3개를 뽑아내야하는데, 배열을 정렬하자니 인덱스 값이 섞여버려서, 3번 반복하며 최소값들을 999값으로 바꿔주었다. 더 나은 방법이 있을 것이다. 추후에 알게되면 수정하자
- K개의 최소 거리 인덱스를 저장하고 그것을 카운팅 해준다. 여기서 최빈값이 최종 레이블이 된다.
- 최종으로 카운팅이 가장 많은 인덱스가 예측값이 된다.
- 레이블을 0,1로 맞춘 이유는 많아지면 최빈값이 잘 안나온다. 실제로는 근처에 비슷한 데이터가 분포할 확률이 높기 때문에 아마 최빈값이 잘 나올듯 한데, 랜덤값이라 레이블이 가지각색으로 나오기 때문에 0과1로 범위를 줄였다.
✍️ Real dataset K - Nearest Neighbor
랜덤값이 아닌 실제 데이터로 KNN 알고리즘을 구현하고 싶어져서 실제 데이터를 찾아보았다.
sklearn의 iris 데이터셋을 많이 이용해서 나는 sklearn의 digits (손글씨) 데이터셋을 이용했다.
- 일단 feature부터 확인했는데, iris 데이터는 feature에 특정 이름이 있던데 이 데이터셋은 pixel_0_0 이런식으로 되어있었다.
- 마지막은 labels인데 추후 사진이 나오지만 0~9 중 고르는 것이다. labels는 각각 사진이 어떤 숫자인지 저장되어있다.
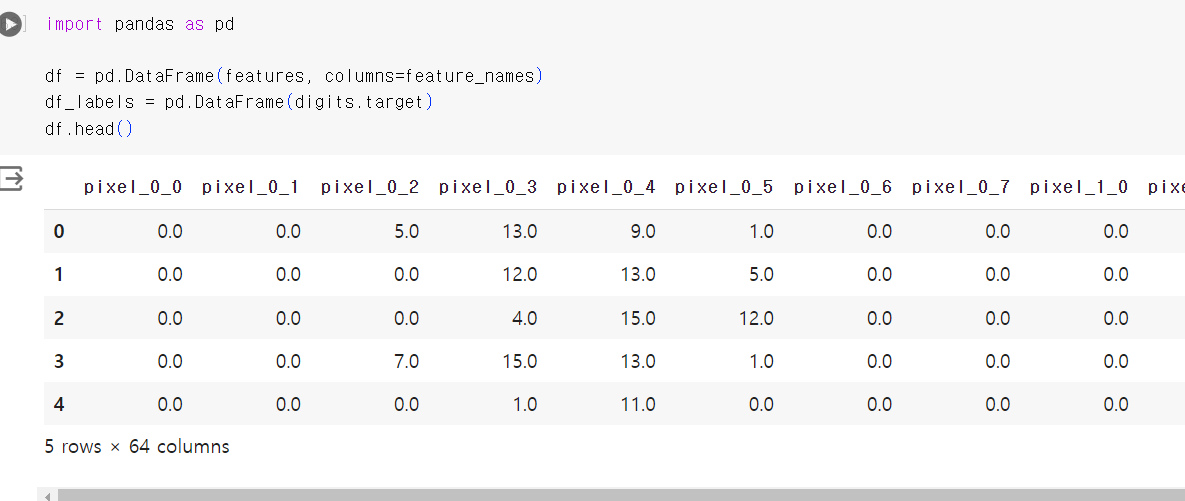
- pandas를 활용하면 이렇게 표로 만들어서 볼 수 있다. 아까 봤던 feature_names가 column 이름으로 들어가 있는 것을 볼 수 있다.

- 이게 존재하는 레이블의 종류이다. 0~9 중 하나의 숫자로 분류할 수 있다.
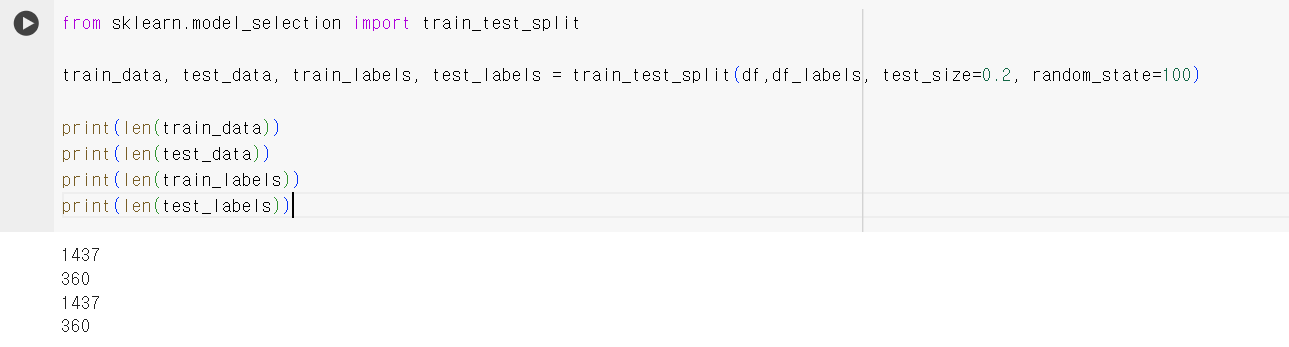
- train, test 데이터셋으로 나누어 준다. 나중에 validation에서 구현해 보려 했는데, KNN 내장함수를 사용하려면 필요하다. train과 test가 1437:360 으로 나누어진 것을 볼 수 있다.
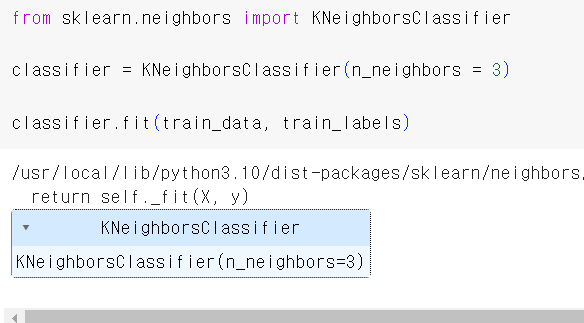
- sklearn에 내장된 KNeighborsClassifier 함수를 써서 KNN알고리즘으로 학습시킨 모델을 만들 수 있다. n_neighbors는 K에 해당하는 값
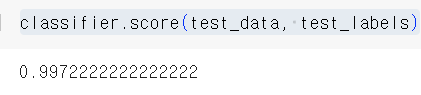
- score을 사용하면 accuracy가 나오는데 꽤 높게 나옴을 볼 수 있다.
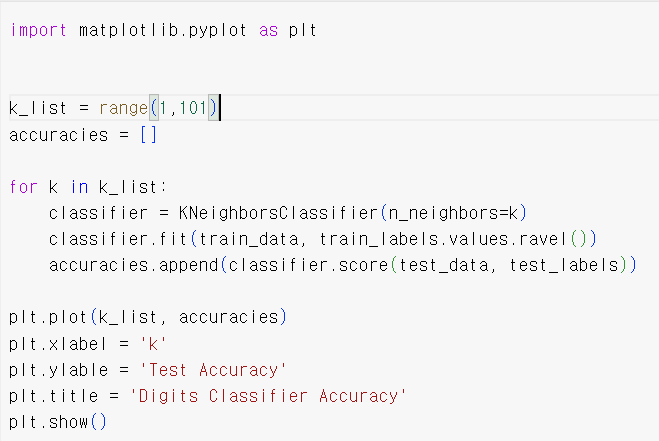
- 이번엔 K를 계속 증가시키며 정확도를 확인해보자
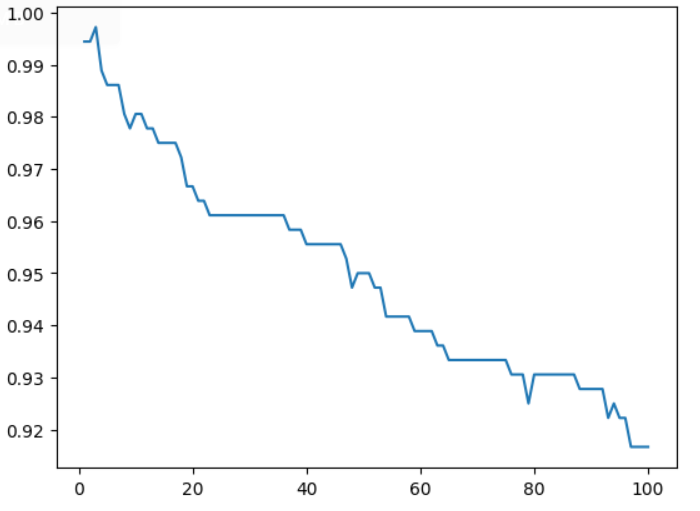
- 나의 경우에는 이런식으로 출력되었다. 당연히 데이터셋의 종류 개수에 따라 다르겠지만, 최적의 K를 정확도를 기반으로 찾아 나갈 수 있다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.metrics import accuracy_score
import numpy as np
digits = datasets.load_digits()
x_data = digits.data
y_data = digits.target
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2,random_state = 100)
knn_model = KNeighborsClassifier(n_neighbors = 3)
knn_model.fit(x_train,y_train)
pred = knn_model.predict(x_test)
accuracy = knn_model.score(x_test, y_test)
# reshape(행, 열)인데 -1은 앞에 거를 만들고 알아서 하라는 뜻
# 코드에서는 1행으로 만들고 열은 알아서 나오는대로 라는 뜻인데 1행으로 만들면 열은 행의 원소 개수 되며 2차원 [[1,2,3 .. ]] 이런 형태가 된다.
# reshape(-1,1)을 하면? 1열로 만드는데 행은 알아서 해라 [[1],[2],[3],[4],[5] ... ] 이런식이 된다. 1열씩만 가진다면 행은 원소 개수만큼 생긴다.
# reshape(-1,2)를 하면? 2열로 만드는데 행은 알아서 [[1,2],[3,4],[5,6]] 이렇게 될것
# 새 데이터를 x_data 중 32번째 행렬로 해보자
new_data = new_data.reshape(1,-1)
new_pred = knn_model.predict(new_data)
# 잘되는지 확인, 예측값이 실제 저장된 레이블과 같으면 된다.
print(new_pred, y_data[32])
# 랜덤으로 8*8 사이즈의 배열은 생성한다.
# 생성값의 범위를 0~16 중 랜덤으로 정한 이유는 밑 코드로 확인했을때
# 16이 가장 컸기 때문
random_array = np.random.randint(17, size=(8, 8))
new_random_array = random_array.reshape(1,-1)
# 랜덤 값을 예측한다. 실행하면 할수록 계속 바뀐다.
# 이건 아마 의미없는 숫자의 나열이므로,지금 내가 아는 바로는 accuracy를 못구한다.
# 틀렸는지 아닌지 모르니까..?
new_random_pred = knn_model.predict(new_random_array)
print(new_random_pred)
- 앞서 했던 내용은 Reference에 작성될 블로그를 보고 적용해본 것이고, 위 코드는 내가 직접 학습을 시켜보았다.
- KNN으로 학습을 시킨 후 x_data 중 32번째 행렬을 모델에 넣어보고 나온 예측값과 y_data[32]와 비교하여 정확하게 분류하였는지 확인하였다.
- 또한 랜덤으로 8*8 사이즈 배열을 생성하여 어떤 숫자에 가장 가까운지 분류하게 하였다.
- 정확도는 내가 아는 범위 내에서는 측정하지 못한다. ( 정확한지 알려면 어떤 사진을 뭐로 분류했는지를 알아야하지만 뭐로 분류한지는 알지만 랜덤값이므로 어떤 사진인지는 알지 못한다.)
✍️ Linear Classification
import numpy as np
data = np.array([[56,231],[24,2]])
# 한개의 열만 가지는 배열이여야 함
x = data.reshape(-1,1)
w = np.array([[0.2,-0.5,0.1,2.0],[1.5,1.3,2.1,0.0],[0.0,0.25,0.2,-0.3]])
b = np.array([[1.1],[3.2],[-1.2]])
# @이 행렬곱을 뜻한다.
print(w@x + b)- Linear Classification은 다음 장에도 계속 나오기 때문에 일단은 f(x,W) = xW + b라는 수식을 파이썬으로 구현하였다.
- 수업 예시에 나오는 4pixel 3classes를 구현하였다.
- @가 행렬곱을 뜻한다.
✍️ Reference
https://velog.io/@hyesoup/KNNK-Nearest-Neighbor-%EB%B6%84%EB%A5%98-%EC%98%88%EC%A0%9C
'AI > algorithm' 카테고리의 다른 글
| [Algorithm] Loss Function, Gradient Descent (1) | 2024.03.05 |
|---|
